Jak działa pamięć LLM-ów
2026-05-24
Jeszcze na początku całego hype'a LLMów niektórzy lubili pisać posty “LLMy nie halucynują, po prostu dają najbardziej prawdopodobny token”. To mi przypomina również “nie ma mleka owsianego — to jest napój owsiany”.
Czy LLMy dają najbardziej prawdopodobny token? Tak. Czy halucynacja to ogólnoprzyjęte nazewnictwo na wynik modelu który nie jest zgodny z rzeczywistością? Tak. To samo dotyczy pamięci. Każdy już jest przyzwyczajony, że to co się dzieje w wątku nazywamy pamięcią krótkoterminową, a jeśli w tym wątku LLM zaciąga informacje z poprzednich wątków — nazywamy to pamięcią długoterminową. Warto jednak wiedzieć jak to działa rzeczywiście.
Pamięć krótkoterminowa
Pamięć krótkoterminowa (co też czasami nazywamy wątkami) to najprostszy sposób realizacji pamięci, w którym pamięć jest przechowywana w kontekście. Cała “pamięć” sprowadza się do doklejania kolejnych informacji i ciągłego zwiększania prompta.
{ "messages": [ { "role": "user", "content": "Jak mam na imię?" } ] }
Na przykładzie dobrze to widać — model “pamięta” ponieważ widzi całą rozmowę w swoim oknie kontekstu. I z tym oknem kontekstu mamy najważniejszy problem: ono jest ograniczone (chociaż czasami może być bardzo duże — nawet milion tokenów).
Ograniczony kontekst
Problem ograniczonego kontekstu spotkał każdego kto próbował implementować agentów (zwłaszcza w erze GPT-4o/o3). Oczywiście najłatwiejszym rozwiązaniem jest ucinanie historii.
Wszystkie wady tego podejścia sprowadzają się do tego, że LLMy są stateless. Jeśli czegoś nie ma w kontekście — model o tym nie wie. W związku z tym na poważnie (przynajmniej w chatbot-like interfejsach) tego nikt nie używa.
Innym sposobem jest użycie compaction — upraszczając — podsumowania konwersacji przez LLM.
Zarówno Claude Code, Codex, OpenCode i inne agentyczne narzędzia obsługują ograniczony kontekst właśnie w taki sposób.
Pamięć długoterminowa
Pamięć długoterminowa to pamięć która pozwala agentowi mieć informacje m.in. z innych wątków. Z implementacją krótkoterminowej pamięci zwykle nie ma żadnych problemów — sprowadza się to do doklejania informacji i zwiększenia prompta. Z kolei długoterminowa pamięć w praktyce realizowana jest za pomocą wektorowej bazy danych oraz wstrzyknięcia informacji do promptu.
Ale co ważne — pamięć długoterminową bardzo często można podzielić na trzy typy:
- semantyczna — fakty i preferencje
- epizodyczna — przeszłe zdarzenia
- proceduralna — zasady i instrukcje
fakty i preferencje
przeszłe zdarzenia
zasady i instrukcje
Każdy z tych typów pamięci wymaga oddzielnego podejścia. Semantyczna i proceduralna są najprostsze — wstrzykujemy informację do promptu bezpośrednio: imię użytkownika, opis pracy (semantyczna), instrukcje opisane tekstem (proceduralna).
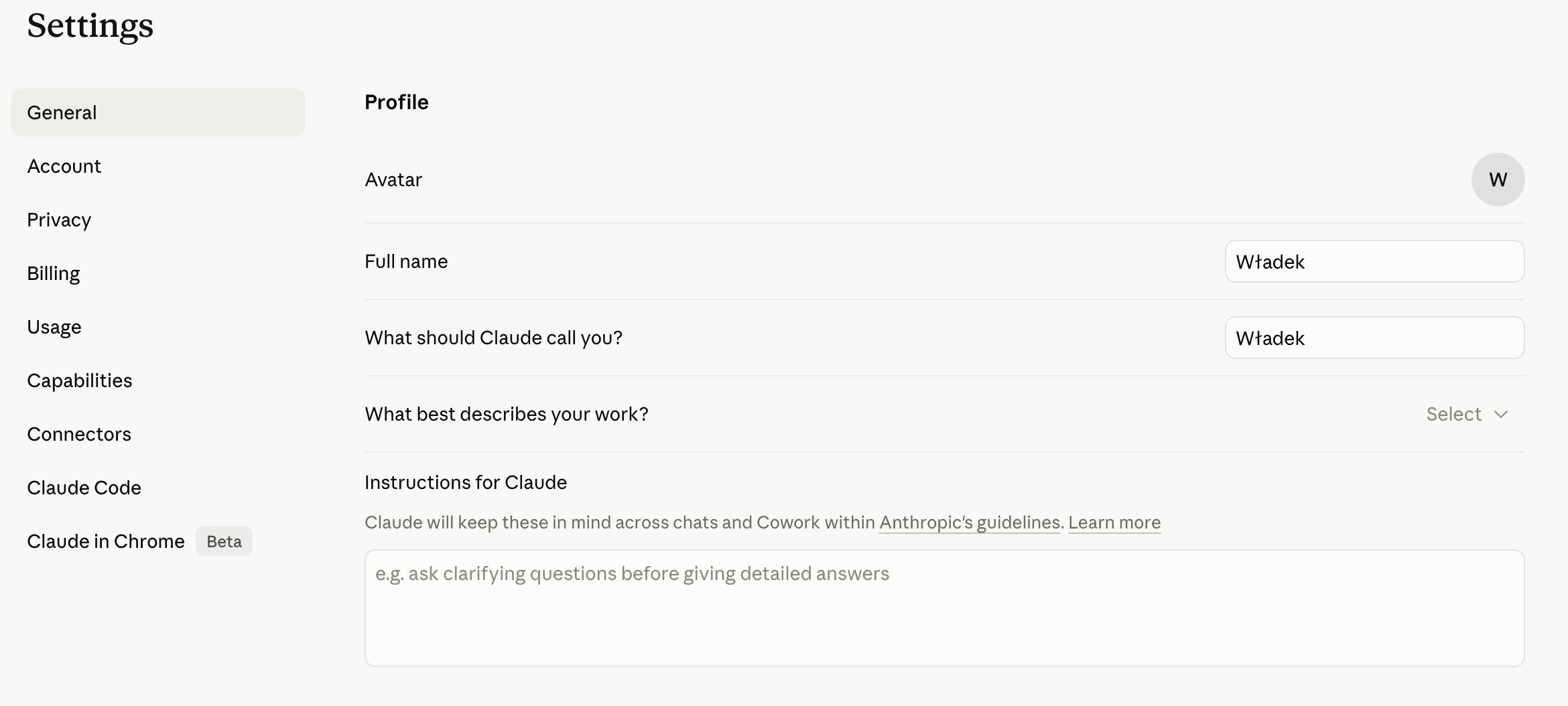
Epizodyczna pamięć jest trochę bardziej skomplikowana. Każde wspomnienie jest zamieniane na embedding. Przy nowej sesji zamiast ładować wszystkie wspomnienia, robimy similarity search — szukamy tych które są najbardziej relewantne do aktualnego kontekstu. Sprowadza się to do implementacji RAG.
Tak samo jak compaction jest dość popularny, pamięć długoterminowa jest zrealizowana prawie w każdym chatbot-like interfejsie: ChatGPT, Claude, Perplexity.
Podsumowanie
Podział na pamięć krótkoterminową i długoterminową wydaje się bardzo intuicyjny, ale pozwala bardziej ustrukturyzować podejście do implementacji i używać odpowiedniego rozwiązania w odpowiednim miejscu.